QCML achieves state-of-the-art accuracy for MNIST on IBM Quantum hardware
Authors: Luca Candelori, Yatin Patel, Sunil Pinnamaneni
The challenge: running MNIST on quantum hardware
The MNIST dataset has been a benchmark for machine learning algorithms for decades. It consists of 70,000 images of handwritten digits, each labeled with the corresponding digit (0-9). The task is to classify each image correctly. The dataset was created by Yann LeCun and his collaborators in the late 1990s and it has served as a testbed for neural networks and other machine learning algorithms since. Convolutional Neural Networks (CNNs) can achieve super-human performance on this dataset, with state-of-the-art CNN ensembles able to achieve accuracies of over 99.5%.
Fig 1: Sample MNIST Digits.
While MNIST can be considered a 'solved problem' for classical machine learning, it still represents a formidable challenge for machine learning models running on quantum hardware. The best published accuracy score obtained on quantum hardware that we could find is about 80% 1, achieved by a quantum support vector machine (QSVM). Relaxing the requirement of running on quantum hardware, the best published accuracy score we could find for a quantum machine learning architecture on a quantum hardware simulator is 99.21% 2, achieved by a hybrid quantum convolutional neural network (HQNN). This is still below state-of-the-art performance, even allowing for fault-tolerance and eliminating the issue of quantum hardware noise. Part of the issue is that standard quantum machine learning models cannot currently handle a large number of features. Typical encoding schemes (e.g. angle encoding) require a number of qubits that scales linearly with the number of features. For a 28x28 pixel image, this would require approximately 784 qubits, which is still beyond the capabilities of current quantum hardware. As a result, dimensionality reduction techniques are needed to reduce the number of features before applying quantum machine learning models, which can lead to a loss of information and sub-optimal accuracy.
Running Quantum Cognition Machine Learning (QCML) on quantum hardware
QCML is not limited by the number of features in the same way as standard quantum machine learning models are. In our paradigm, data is encoded as ground states of Hamiltonians, and the size of the Hamiltonian (i.e. the number of qubits required) is a hyperparameter controlling the size of the model; in QCML, an image could in principle be encoded using a single qubit, though in practice a model of this size is not expressive enough to achieve high accuracy on MNIST. To obtain good accuracy on GPUs we typically use the equivalent of 5-6 qubits, right at the limit of what is practical with classical ground state solvers on a dataset of this size. Switching to quantum hardware allow us to lift this limitation, unlocking the possibility of training more expressive QCML models that can achieve higher accuracy on MNIST.
In our joint work with IBM Quantum3, we demonstrated that QCML models can be trained on quantum hardware using a hybrid quantum-classical training method. The ground state calculation in this method is done on quantum hardware by Sample-Based Kylov Quantum Diagonalization (SKQD), a recent algorithm developed by IBM4. Here, we extend this approach to MNIST.
Model Architecture
Because the dataset consists of images, we first pass each image through a ResNet (residual network) layer to extract 2D-convolutional features that better capture the geometry of each digit, similar to the HQNN architecture 2. The ouput of the ResNet consists of 4612 features that are flattened and fed into a QCML layer, with no need for dimensionality reduction. A modified QCML layer consisting of 2-local Pauli string Hamiltonians is employed, as in 3. The QCML layer is trained using approximate gradient descent, where the gradients are estimated using finite differences. The ground state calculation is done on quantum hardware via SKQD. This model architecture is summarized by the following diagram
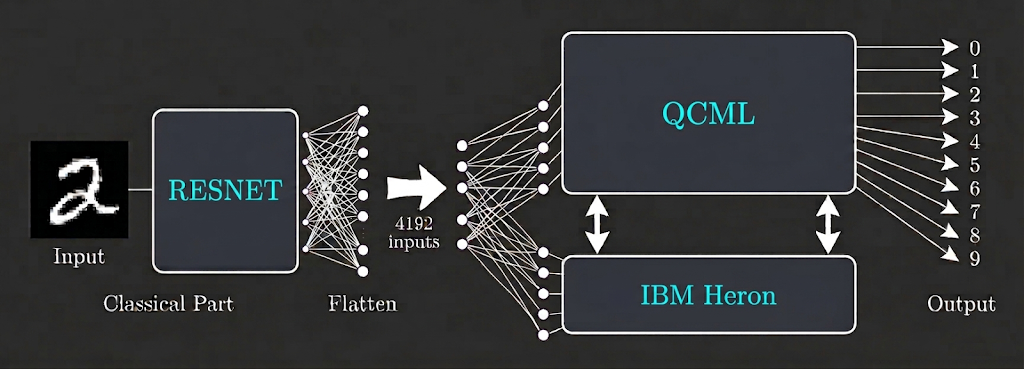
QCML architecture diagram. The ResNet layer extracts convolutional features from the input image, which are then fed into a QCML layer. The ground state calculations for QCML are done on quantum hardware (IBM Heron) via SKQD.
The role of quantum computation
The QCML layer uses SKQD, which harnesses the sampling power of quantum hardware. For this project, we used the IBM Heron processor revision 2. The key idea behind SKQD is to evolve a given Hamiltonian on an initial ground state ansatz and then sample to produce a subspace that contains the majority of the ground-state support. The Hamiltonian is then projected onto this subspace and an approximate ground state is extracted by classical diagonalization methods. In this way we can use quantum hardware to find an approximate ground state of very large Hamiltonians, that would be intractable to find classically. For example, in our joint work with IBM Quantum3, we were able to test QCML models consisting of 50-qubit Hamiltonians, well beyond the reach of classical ground state solvers.
Results
The accuracy as a function of epochs is shown in Fig 2. QCML on quantum hardware achieves a peak accuracy of 99.57%, well above the previous record of 80% on quantum hardware and within the range of state-of-the-art CNN ensembles on classical hardware. Note that in our approach we did not use any data augmentation techniques, which are commonly used to boost the performance of classical machine learning models on MNIST, and we did not ensemble.
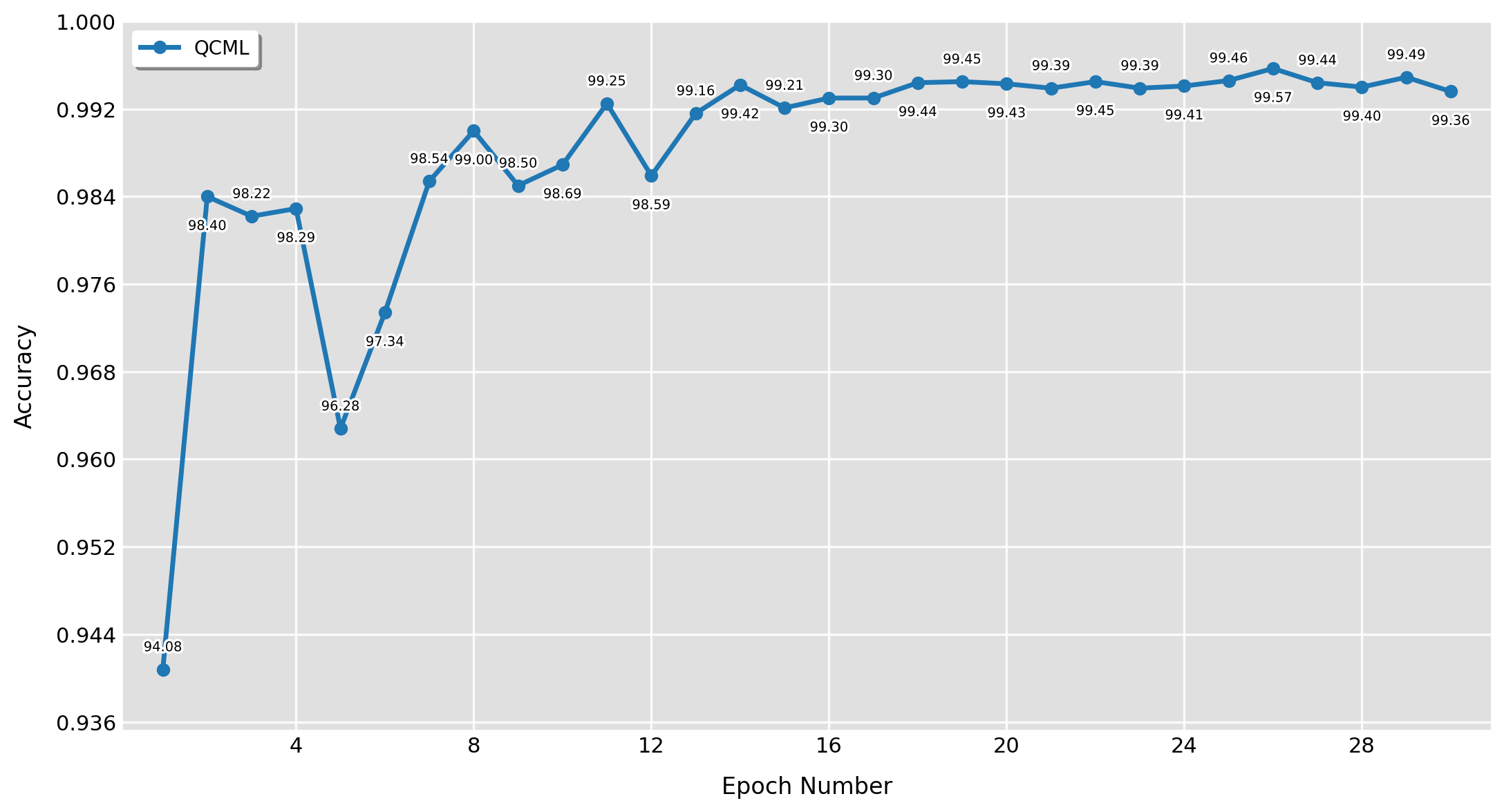
Fig 2: Accuracy vs Epochs.
At this level of accuracy, the model makes only 43 errors out of 10,000 test images. Fig 3 shows the true vs predicted labels for some of these errors. We can see that many of the errors are between digits that are visually similar and poorly handwritten, matching human performance on this task.




Fig 3: True vs Predicted Labels for some of the 43 total errors made by the QCML model out of 10000 test images.
It is important to analyze the training curves of our model, to assess the robustness of our results. After the first epoch, we see an accuracy of 94.08%, which increases in expectation over the remaining epochs. We see some noisy fluctuations, but they are relatively mild. Similarly, the training loss also decreases over the 30 epochs with a minor fluctuation at epoch 6. With the decline in training loss, we also see a decline in test loss.
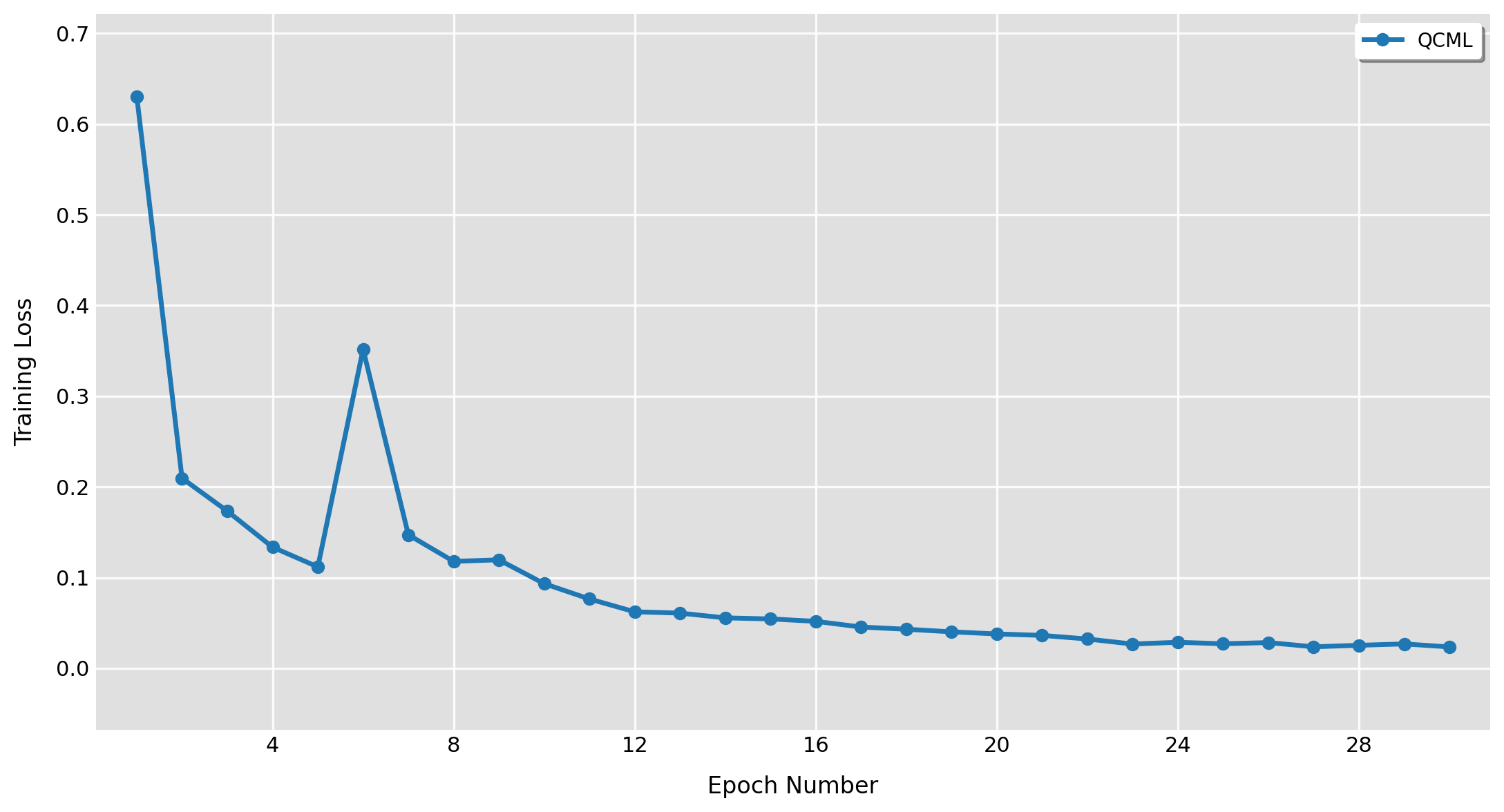
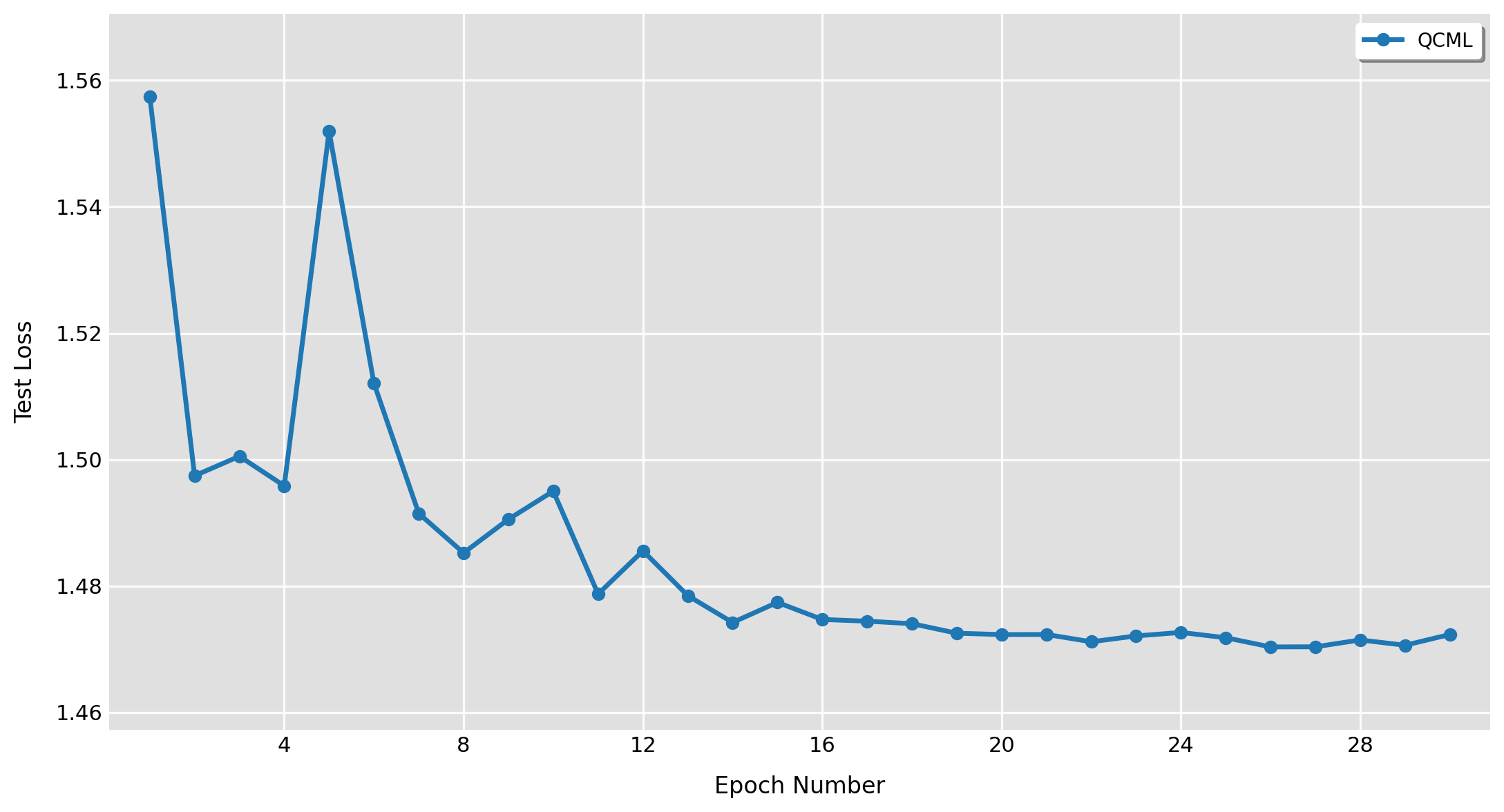
Fig 3: Training and Test Loss vs Epochs.
In many ways, this behavior is similar to what one would expect when training a ResNet layer followed by an attention layer. However, our training procedure differs from standard neural network training because we use approximate gradients instead of the exact analytical gradient. In addition, we use quantum hardware to sample a subspace of the whole subspace. The fraction of the whole subspace as a function of epoch is plotted in Fig. 4 (left). It's interesting to observe that we sample only 18% of the whole space. The fact that we can achieve state of the art results while sampling only 18% of the subspace shows that ML training routines can potentially be optimized through sampling and approximate gradients. Furthermore, the subspace overlap from point to point is no more than 40% (Fig. 4, right).
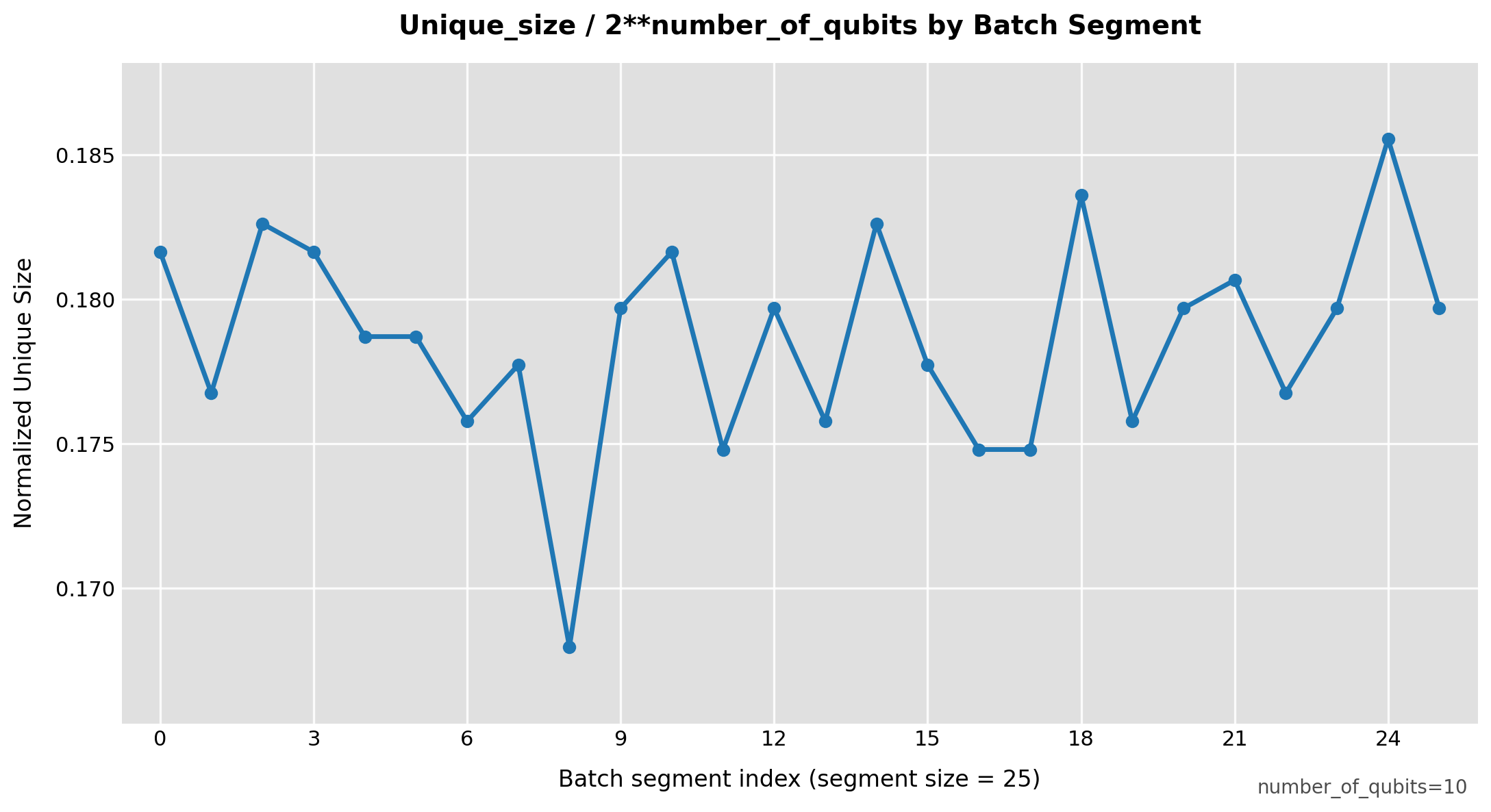
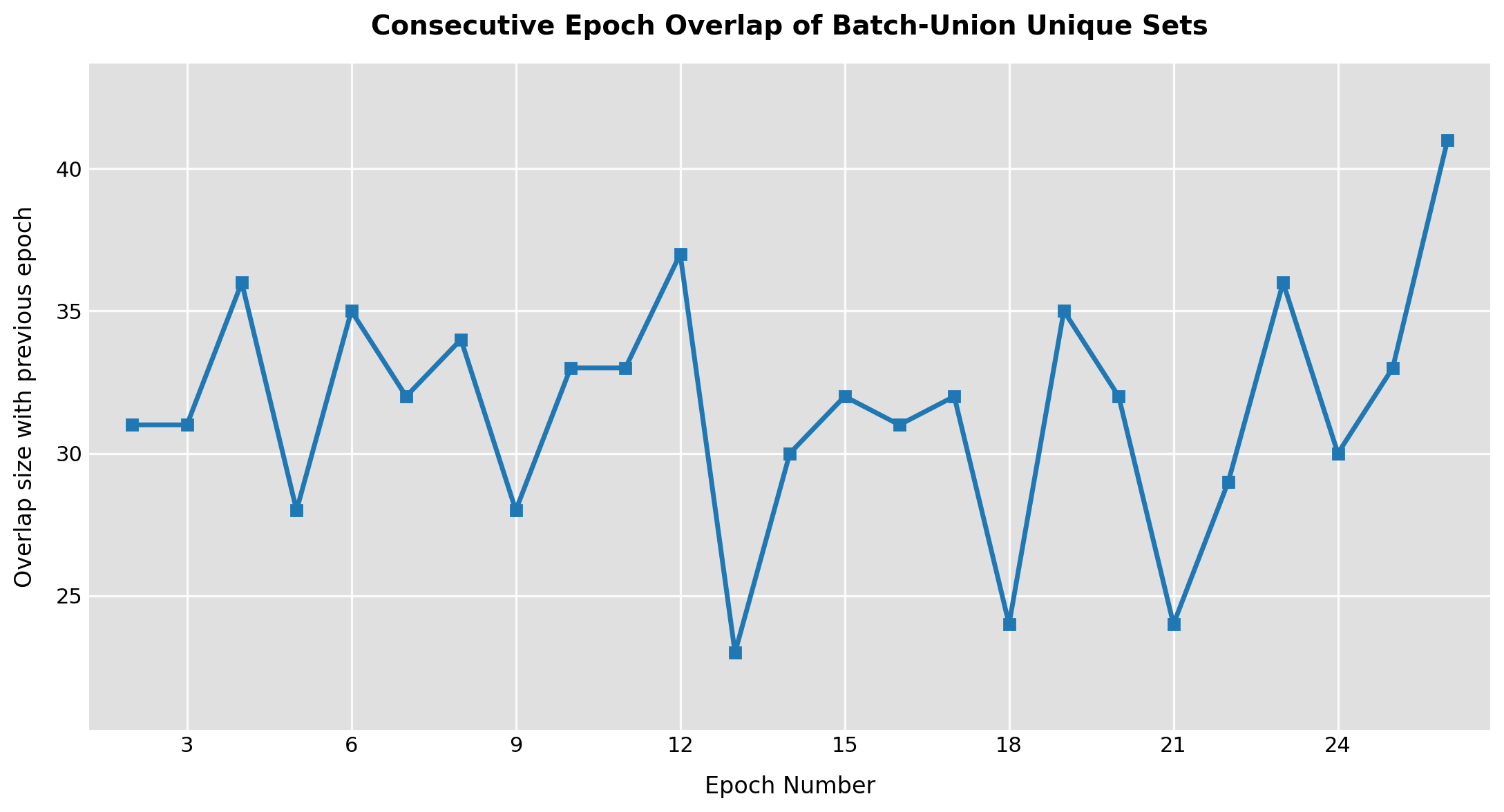
Fig 4: Subspace Coverage and Subspace Overlap
Conclusion
To our knowledge, this is the first example of a machine learning model trained on real quantum hardware (not simulated) that achieves state-of-the-art performance on MNIST. Our approach is able to overcome the limitations of current quantum hardware in several ways:
-
QCML's new data representation scheme allows us to encode high-dimensional data with a manageable number of qubits, avoiding the need for dimensionality reduction techniques that can lead to loss of information.
-
By employing exclusively Pauli 2-local Hamiltonians we are able to taylor the model architecture to the requirements of the IBM Heron Quantum processor. This drastically reduces running time and quantum error.
-
Our approximate gradient and sampling approach is robust to quantum noise and other hardware limitations, allowing us to train the model effectively without the need of fault-tolerant qubits.
Our experiment also demonstrates the scalability of QCML on quantum hardware, potentially beyond the regime where classical simulation is possible. While 10 qubits seem sufficient to achieve state-of-the-art performance on MNIST, our architecture easily scales to higher qubits counts, which could allow us to tackle more complex datasets and tasks in the future.
References
Footnotes
-
Exploring the Capabilities of Quantum Support Vector Machines for Image Classification on the MNIST Benchmark (2023), Slysz et. al. , ↩
-
https://arxiv.org/abs/2304.09224 Quantum machine learning for image classification (2023), Senokosov et. al. ↩ ↩2
-
https://arxiv.org/pdf/2601.0323 Shallow-circuit Supervised Learning on a Quantum Processor (2026) ↩ ↩2 ↩3
-
https://arxiv.org/abs/2501.09702 Quantum-Centric Algorithm for Sample-Based Krylov Diagonalization (2025) ↩